Yesterday, while googling about the es_rejected_execution_exception error, I learn about the how an index is being written into Elasticsearch(ES). Thus, I think is best to write an article about this :)
Background
Before deep into the theory, there is some terminology we should understand first.
- Document - The content / data
- Index - The logical namespace of a collections of documents
- Shard - Horizontal partition of an index (In ES, every shard is a self-contained Lucence index)
- Replica - Replicate of shard
- Node - A single server that host multiple shard
- Cluster - A group of one or more connected node
In ES, each index is divided into shards and each shard can have multiple copies (which is known as replication group). This replication group must be synchronized with each other whenever a document is added or deleted. This process of keeping all the shards in sync is known as the data replication model.
The data replication model that ES reference is primary-backup model. In this model, we will always have ONE primary shard inside a replication group and the rest will act as replica shard. The primary shard will serve as the main entry point for all the indexing operations. Once an operation is accepted by the primary, it will then get replicated and send to all replicas.
Write Model
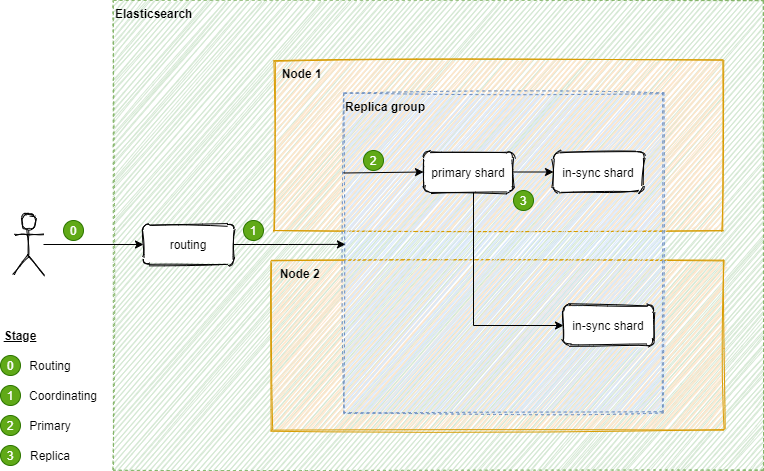
Every index operation in ES will first go through a component called routing which resolves the index to a replication group. After the replication group is identified, it will then go through three stages: coordinating, primary, and replica.
-
Coordinating
The operation request is forwarded internally to the primary shard.
-
Primary
After the primary shard received the operation request, it will start to validate the operation and reject if the structure is invalid. If the validation passed, primary shard will then execute the operation locally, and only forward the operation to replica if success. The operation request will only be forwarded to in-sync replicas (the replica that processed the latest and up-to-date operation). ES will take care of the in-sync replica identification.
-
Replica
Once the in-sync replica received the operation request, it will perform the operation locally. This stage is consider done when every in-sync replica successfully performs the execution.
Failure Handling
There are many possibilities that things can go wrong during indexing e.g. disk corruption, node disconnected, misconfiguration. We will talk about some of the scenarios.
- Primary shard failed
- The node that hosts the primary shard will send message to master node. The index operation will be held (up to 1 minute, by default) while waiting for the master node to promote a replica shard to be the new primary shard. After the replica shard is successfully promoted to primary, the operation will be forwarded to it for processing.
- The master node will actively monitor the health of each node and might demote the primary shard if the node is not healthy.
- The primary shard will use replica to check its primary status validity. There is some case that the primary shard might not notice that it has been demoted. The replica will reject the operation request from the primary shard because it no longer the primary. Then, it will reach out to the master node and will learn that it has been replaced. The operation will then forwarded to the new primary shard.
- Replica shard failed
- When the primary detects that any of the in-sync replica shards does not respond as expected, it will send request to the master node for removing that particular replica from the in-sync replica list. The primary shard will only acknowledge the success of the operation once the master node acknowledges the replica shard removal complete.
Read Model
Read operation in ES is super lightweight. As all of the replica shards are identical and in sync, the read request can be done by the nearest node.
-
Read request received by a node.
-
The node will resolve the relevant replication group and select active shard (can be primary or replica) with adaptive replica selection (by default if
cluster.routing.use_adaptive_replica_selection = trueelse round-robin method will be used).This method selects an eligible node using shard allocation awareness and the following criteria:
- Response time of prior requests between the coordinating node and the eligible node
- How long the eligible node took to run previous searches
- Queue size of the eligible node’s
searchthreadpool
-
Send read requests to the selected shard.
-
Combine the result and response to the caller. (Optional. Can be skipped if only one shard is relevant )
Failure Handling
When a shard fails to respond to a read request, the coordinating node will send the request to another shard within the same replication group. This will be repeated until there is no available shard in the replication group.
Conclusion
In this article, we cover the basic read/write model of ES. We also touch on some of the failure handling behavior that ES will take when there is any failure with the request.