When we talk about data lake in enterprise, the first term that normally will pop up would be Apache Hadoop. Hadoop seem to be the no brainer solution for most of the company that thinking to maintain a data lake. However, there are few things that I don’t really like about it e.g. cost (hosting a Hadoop cluster is really expensive) and steep learning curve.
Welcome, Delta Lake, the next generation data lake.
Delta Lake
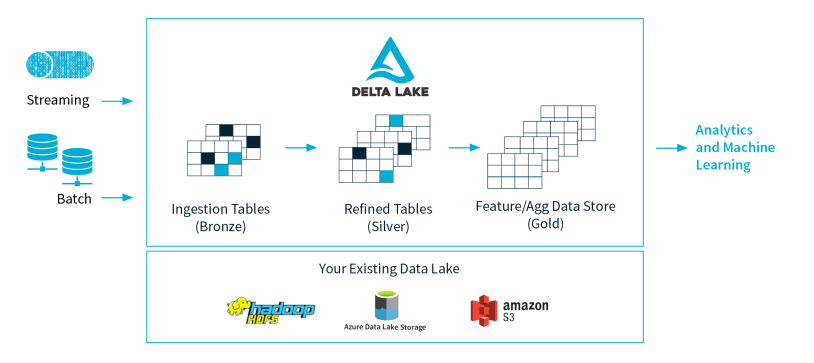
Delta lake is an open source project that created by Databricks. Delta lake is introduced in the documentation as :
Delta Lake is an open source project that enables building a Lakehouse architecture on top of data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing on top of existing data lakes.
Below is some cool key feature that Delta lake provide :
- ACID transaction - It is always a very tedious job to maintain data integrity and making sure reader always read consistent data in data lake. This will definitely make data engineer life easier.
- Data versioning - Delta lake creates a snapshot/versioning of data which enabling access and revert to earlier versions of data for audits, rollbacks or to reproduce the experiments.
- Unifying Batch and Streaming storage - Delta lake can be the storage table for Spark batch job and sink in Spark streaming.
- Easy migration from Hadoop - Delta lake support storing the data in HDFS which provide a way for enterprise to migrate their data lake to Delta lake without worry about the legacy Hadoop cluster. [ Hadoop is dead, long live Hadoop :) ]
Quick Start
In this blog post, I will quickly show you how to read / write data into Delta Lake that storing data in local file, S3 and Azure Blob Storage.
Pre-requisite
Make sure you have install :
-
Java version 8 and above
-
Spark installed (Ubuntu setup guide)
Local File
If the local file system does not support atomic rename, the concurrent transaction writes on Delta lake will not work as expected.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from delta import *
import pyspark
# start spark session
builder = pyspark.sql.SparkSession.builder.appName("MyApp") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = spark = configure_spark_with_delta_pip(builder).getOrCreate()
# create table
spark.sql("CREATE OR REPLACE TABLE delta.`/tmp/delta/events` ( date DATE, eventId STRING, eventType STRING, data STRING) USING DELTA")
# insert data to table
spark.sql("INSERT INTO delta.`/tmp/delta/events` values('2021-05-01', 'id123', 'type1', 'abc')")
# read data from table
df = spark.sql("select * from delta.`/tmp/delta/events` ").show()
df.show()
# load into spark data frame
df = spark.read.format("delta").load("/tmp/delta/events")
df.show()
AWS S3
To interact delta table that store in AWS S3, you will need to obtain the access key and secret key from AWS portal.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from pyspark.sql import SparkSession
from delta import *
import pyspark
# start spark session
builder = pyspark.sql.SparkSession.builder.appName("MyApp") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")\
.config("spark.hadoop.fs.s3a.access.key", "<aws access key>")\
.config("spark.hadoop.fs.s3a.secret.key", "<aws secret key>")
spark = spark = configure_spark_with_delta_pip(builder).config('spark.jars.packages', 'org.apache.hadoop:hadoop-aws:3.3.1').getOrCreate()
# create table
spark.sql("CREATE OR REPLACE TABLE delta.`s3a://s3-deltalake-poc/events` ( date DATE, eventId STRING, eventType STRING, data STRING) USING DELTA")
# insert data to table
spark.sql("INSERT INTO delta.`s3a://s3-deltalake-poc/events` values('2021-05-01', 'id123', 'type1', 'abc')")
# read data from table
df = spark.sql("select * from delta.`s3a://s3-deltalake-poc/events` ").show()
df.show()
Azure Blob Storage
To interact delta table that store in Azure Blob Storage, you will need to obtain the SAS key from Azure portal.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from pyspark.sql import SparkSession
from delta import *
import pyspark
# start spark session
builder = pyspark.sql.SparkSession.builder.appName("MyApp") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")\
.config("spark.delta.logStore.class", "org.apache.spark.sql.delta.storage.AzureLogStore")\
.config("fs.azure.sas.<your-container-name>.<your-storage-account-name>.blob.core.windows.net", "<complete-query-string-of-your-sas-for-the-container>")
spark = spark = configure_spark_with_delta_pip(builder).config('spark.jars.packages', 'org.apache.hadoop:hadoop-azure:3.3.1').getOrCreate().getOrCreate()
# create table
spark.sql("CREATE OR REPLACE TABLE delta.`wasbs://<your-container-name>@<your-storage-account-name>.blob.core.windows.net/<path-to-delta-table>` ( date DATE, eventId STRING, eventType STRING, data STRING) USING DELTA")
# insert data to table
spark.sql("INSERT INTO delta.`wasbs://<your-container-name>@<your-storage-account-name>.blob.core.windows.net/<path-to-delta-table>` values('2021-05-01', 'id123', 'type1', 'abc')")
# read data from table
df = spark.sql("select * from delta.`wasbs://<your-container-name>@<your-storage-account-name>.blob.core.windows.net/<path-to-delta-table>` ").show()
df.show()
Conclusion
Delta lake is definitely the rising star in data lake that you should never ignore. However, at the time of writing, the choice of mature Delta lake connector still very limited, Apache Spark remains the main access point if you want to use Delta lake.
Stay tune for more connector information on this page.
Reference
- Delta Lake - Introduction - link
- Delta lake with Spark: What and Why? - link
- Delta Lake – The New Generation Data Lake - link