In previous blog post, we walk through some basic CRUD operations on Delta Lake. However, if you’re a Java application developer, you might just want to focus on the SQL query logic without having to worry about the implementation details of Spark job.
“Can I access Delta Lake with JDBC? “
“Yes. Use Spark Thrift Server (STS)”
Spark Thrift Server (STS)
STS is basically an Apache Hive Server2 that enable JDBC/ODBC client to execute queries remotely to retrieve results. The differences between STS and hiveSever2 is that instead of submitting the SQL queries as hive map reduce job STS will use Spark SQL engine. With STS, you will able to leverage the full spark capabilities to perform the queries.
Start/Stop Server
Run the following command in the Spark distribution folder (SPARK_HOME).
Start server with Spark local mode:
1
2
3
4
sbin/start-thriftserver.sh \
--conf spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension \
--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog \
--packages 'io.delta:delta-core_2.12:1.0.0'
Start server on existing Spark cluster:
1
2
3
4
5
sbin/start-thriftserver.sh \
--conf spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension \
--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog \
--packages 'io.delta:delta-core_2.12:1.0.0' \
--master spark://<spark host>:<spark port>
Start server with S3 aceess credential:
1
2
3
4
5
6
7
sbin/start-thriftserver.sh \
--conf spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension \
--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog \
--conf spark.hadoop.fs.s3a.access.key=<s3 access key> \
--conf spark.hadoop.fs.s3a.secret.key=<s3 secret key> \
--packages 'io.delta:delta-core_2.12:1.0.0, org.apache.hadoop:hadoop-aws:3.3.1' \
--master spark://<spark host>:<spark port>
Stop server:
1
sbin/stop-thriftserver.sh
Connect with JDBC
To test the JDBC connection we will use the beeline tools that package in Spark’s bin folder.
1
bin/beeline
Connect to STS :
1
beeline> !connect jdbc:hive2://localhost:10000
** Beeline will prompt for username and password. In non-secure mode, simply enter the username on your machine and a blank password. For secure mode, please follow the instructions given in the beeline documentation.
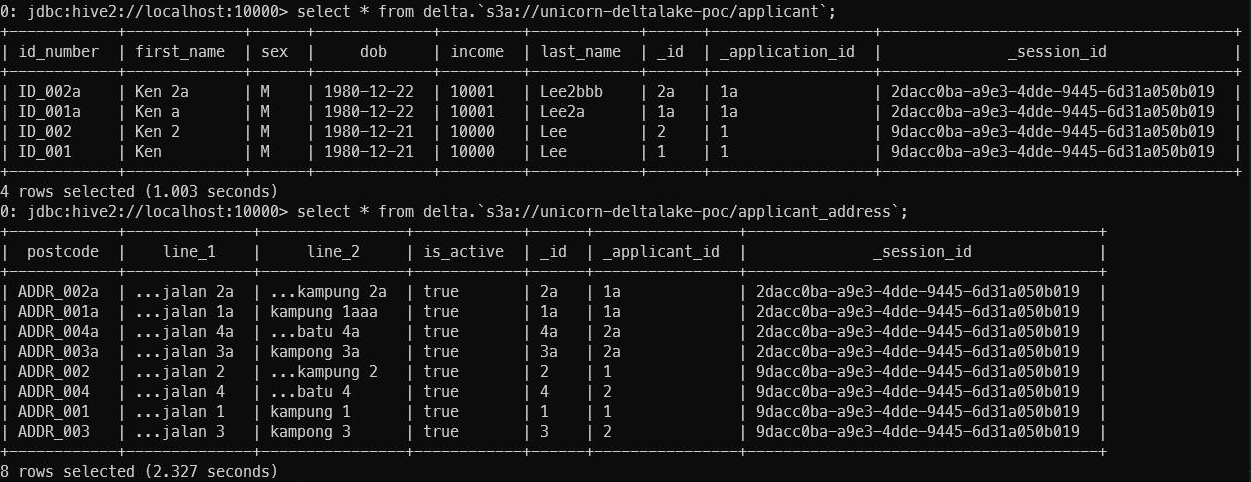
Once connected you can simply issue the SQL queries.
Conclusion
In this blog post, we looked into using Spark thrift server to query Delta lake using JDBC.
Reference
- Disrtibuted SQL Engine - link
- Thrift JDBC/ODBC Server — Spark Thrift Server (STS) - link
- HiveServer2 Clients - link